Term frequencies are a way “count” or represent a term in a document. Term frequencies are seen in all things Text, fromBag of Words and document term matrix to information retrieval. In my previous text, Bag of Words and Document Term Matrix posts, I use the function definition of tf(term, document) = count of the term in the document. This is probably the most common function definition for term frequency. We count “terms” and not “words” for term frequency. Some of the terms we may be interested in may not be an actual word.
In reality, term frequency can be calculated with any function that you want to use. Depending on what you are attempting to do with term frequencies. There is no one right answer for calculating term frequencies. In this post I will list a few of the more common term frequency calculations.
The data I will use demonstrate the results of term frequencies using some of the more common definitions for TF calculation in the context of a Document Term Matrix. The corpus used for the examples seen below include the main text from 4 different blog posts:
- BOW.txt = http://www.darrinbishop.com/blog/2017/09/text-analytics-bag-of-words/
- DTM.txt = http://www.darrinbishop.com/blog/2017/10/text-analytics-document-term-matrix/
- Text.txt = http://www.darrinbishop.com/blog/2017/09/start-treating-your-text-like-text-data/
- TF.txt = this post
I have preprocessed these documents by removing stop words, converting to lower case and stemming. This preprocessing is a common practice when working with text.
Binary or Boolean-Based Term Frequency
The simplest term frequency calculation is the binary or Boolean calculation.
tf(term, document) = 1 if term exists, 0 if term does not exist.
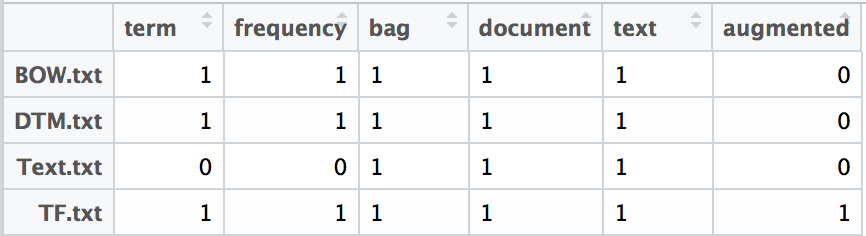
This calculation an existence definition. If term t exists in document d then there is a count of 1. If term t exists more than once in document d the count is still 1. In this context 1 or 0 is used as a binary representation for existence. This term frequency definitions allows a developer to use Boolean logic to analyze text. I have seen this definition used for very simple search and ranking functionality. It would be simple to answer the questions such as “which document has the term frequency?” or “which documents have the word text and augmented?” It is not very easy to suggest that one document is more about a term than another document. For example, it would be hard to suggest that BOW.text is more about the term “bag” than any other document.
Term Count
The most common definition for term frequency is simply counting the term’s occurrence in a document.
tf(term, document) = term count
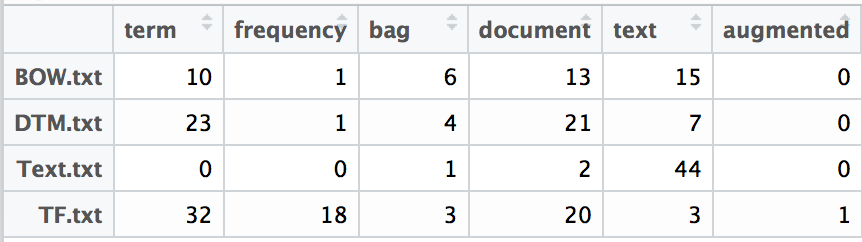
The term frequency tf for term t in document d is the count of the term in the document. Unlike the Binary or Boolean definition, terms that appear multiple times in a document d will have a tf > than 1. In this representation we can determine which term might be more important in a document or corpus. Using term counts does help us decided which terms are “more important” in a document and possibly what key topics a document is about. For example, it does seem that DTM.txt is likely to be more about terms and documents than Text.txt.
Wikipedia lists a few other common calculations for term frequency. Two of these are normalized versions of term frequencies. Normalization can help minimize the affect of longer and shorter documents. For example, a short document about football would probably have a lower word count for the word football than a long document about football . Normalization allows us to compare apples-to-apples.
Term Frequency Adjusted for Document Length
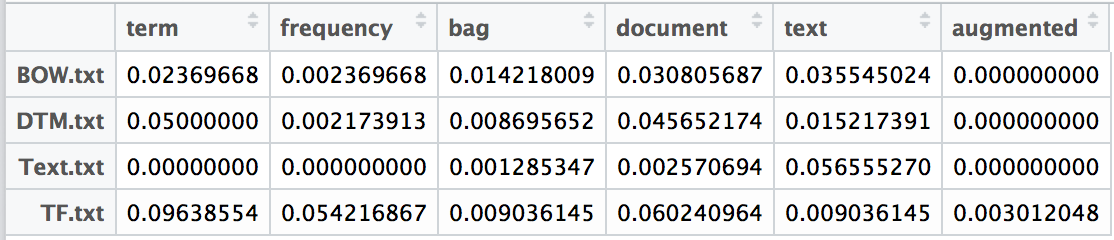
This definition of term frequency divides the term count for term t in document d by the total term count of document d. This normalizes the word on the length of a document. Without this normalization a term in a long document will appear to be much more important than a term in a shorter document.
tf(term, document) = term count / total term count in document
Augmented Frequency
Augmented frequency is another normalized term frequency definition. In this definition the tf is calculated by dividing the count of term t by largest term count in a document. This is a normalization on the most frequent term.
tf(t,d) = term frequency / highest term frequency in document
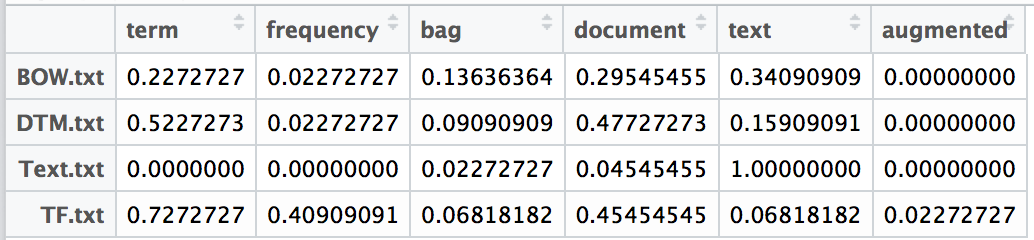
I have not seen this specific definition before and I am not sure where it would fit in for usefulness. If you have seen it before and have an opinion on when it might be used please reach out to me.
Logarithmic-Scaled Term Frequency
The logarithmic scaled term frequency definition is one that I found while reviewing the Wikipedia entry for Term Frequency.
tf(t,d) = log(1 + term count in document) or 0 if term count = 0
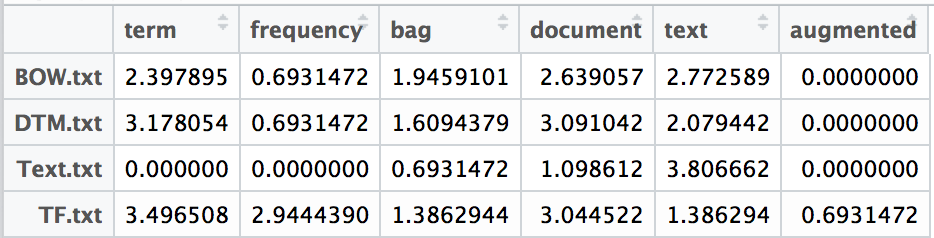
Using a logarithmic function for the definition is and sounds complex but it really is simple. The logarithmic function acts similar to a weight. Each additional occurrence of a term has a smaller weight. In this case, each term occurrence for term t is not equal. The more the term t occurs in document d the weight of the additional count is smaller on a logarithmic scale. Below is a example plot of the logarithmic scale. The bottom axis represents the term frequency of a single term t. The vertical axis represents the “weight” or effect of term t with a specific term count. The weight of a term between 1 and somewhere around 50 or 100 increases rapidly with each new occurrence of the term. Once we reach the elbow of the plot the weight or effect more terms in the same document has rapidly diminishes. 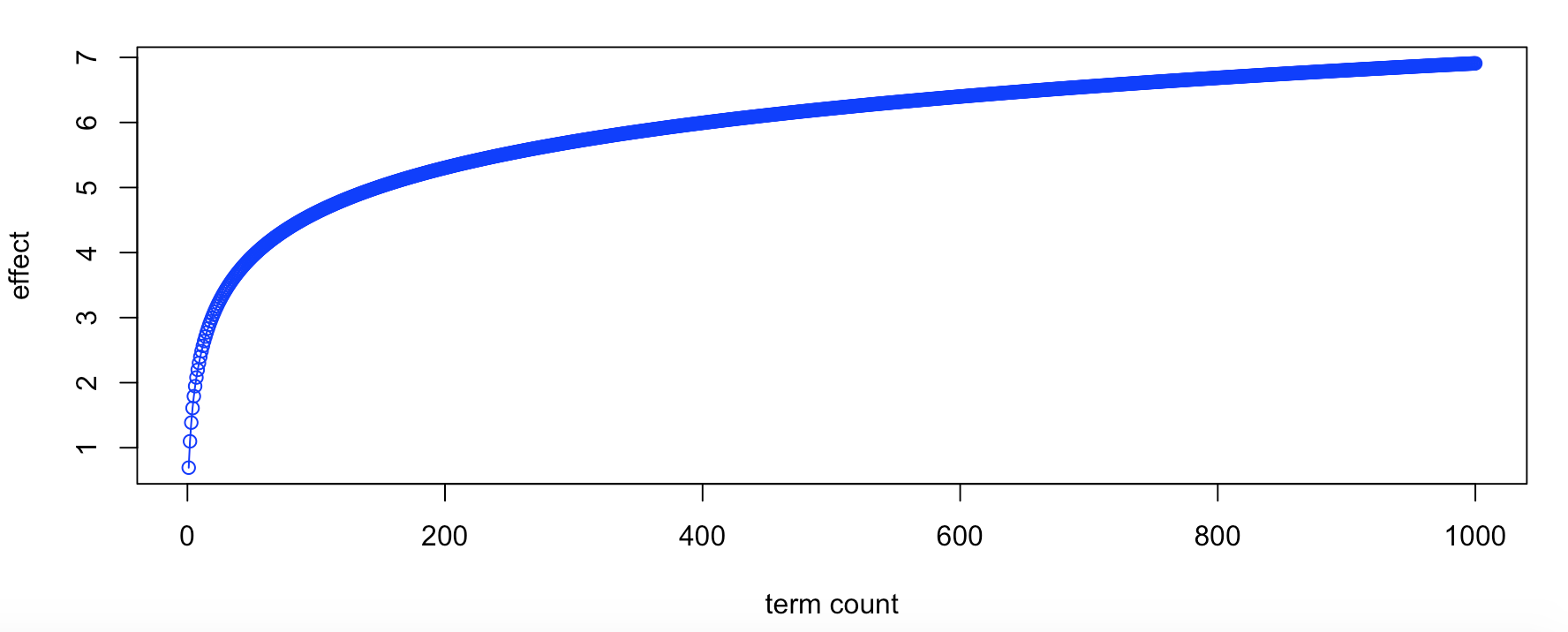
This type of dynamic weighting is commonly used in ranking algorithms. This type of scale can limit the effect of an author from cramming a keyword in a document hoping for a higher search ranking. With a logarithm-based function the first appears of a term is considered important but for each occurrence of the term the “value” of the term decreases quickly to a point where additional terms provide little value.
Why Care About Term Frequency
Term frequency is one of the key metrics for text analytics. These values can help point out key terms for a document or corpus. With these data points you can categorize documents, find similar documents and even rank documents in search results. Term frequencies are also commonly used in machine learning experiments as features.
There is no one definition for term frequency. I have listed a handful of definitions but there is an infinite number of definitions possible. Which definition you choose to use will be dependent on your project requirement and goals.
Drop me a comment or email to discuss how your organization can use text data as a strategic advantage for your organization!

